Nowadays it’s very common to build systems focused on events where events drive the flow of data and interactions, aka Event-driven architecture.
Simply put, Apache Kafka is an event-streaming platform. It does the following,
Single platform to publish and subscribe to events.
Process real-time streams of events.
All events are stored.
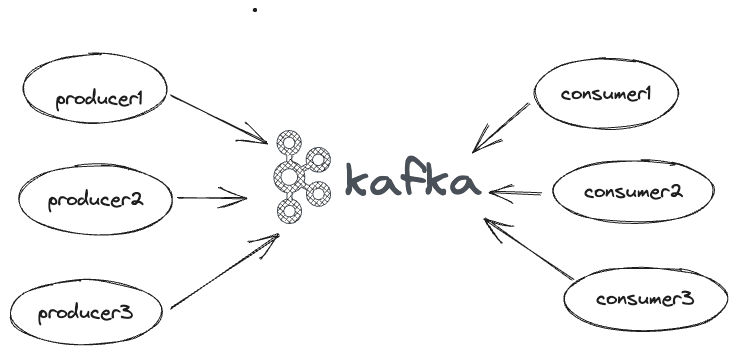
On a high level, Kafka has Producers and Consumers as shown above.
Producers - They push events (obviously).
Consumers - They consume. The arrow towards Kafka from the consumer indicates it polls the messages from Kafka.
Now let’s breakdown Kafka,
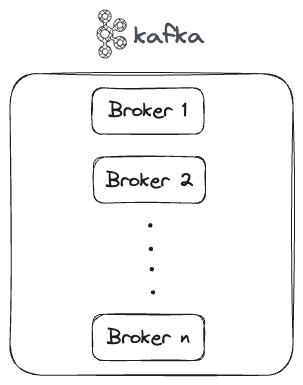
A Kafka cluster consists of multiple brokers, each broker is running a Kafka process and stores the events in the disk. A broker can be easily referred to with any legacy terms such as machines/servers or can be containers or VMs etc.
We can deploy and manage a Kafka cluster or use any managed services such as Confluent Cloud, AWS MSK etc.
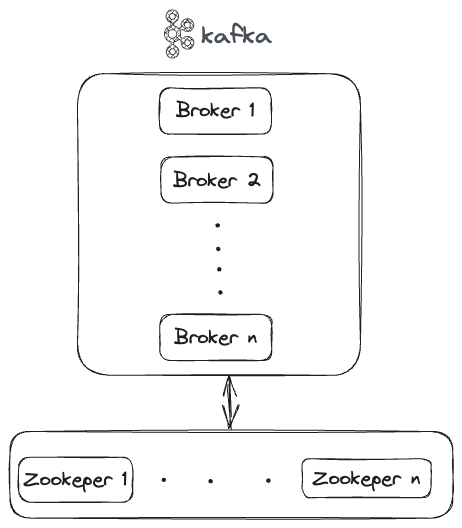
You might be wondering what’s the new component shown at the bottom. It’s Zookeeper.
Kafka users Zookeeper for,
Cluster management
Metadata handling.
Failure detection/recovery, leader election.
ACLs etc.
A new protocol based on an event-based variant of the Raft consensus protocol was introduced in KIP-500 to remove Apache Kafka’s dependency on ZooKeeper for metadata management called Apache Kafka Raft (KRaft).
With the release of Apache Kafka 3.5, Zookeeper is now marked deprecated. It is expected to be removed in version 4.0.
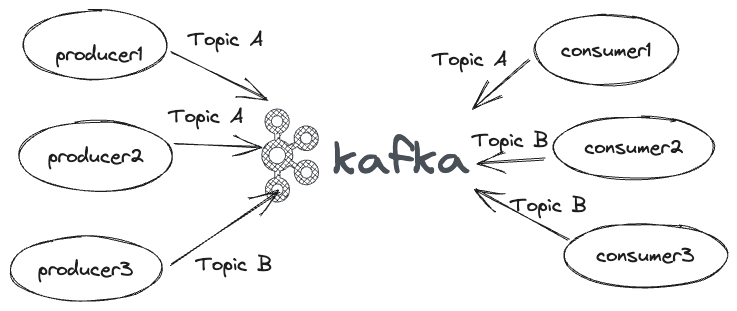
A Topic is a collection of related events. Data is propagated from producers to consumers through these topics. There can be multiple producers writing to a topic or a single producer writing to multiple topics. Similar is the case with the consumers as well.
Currently, Kafka can have conceptually as many as hundreds of thousands of topics in a Kafka cluster. With KRaft mode it is said to be in millions [Source].
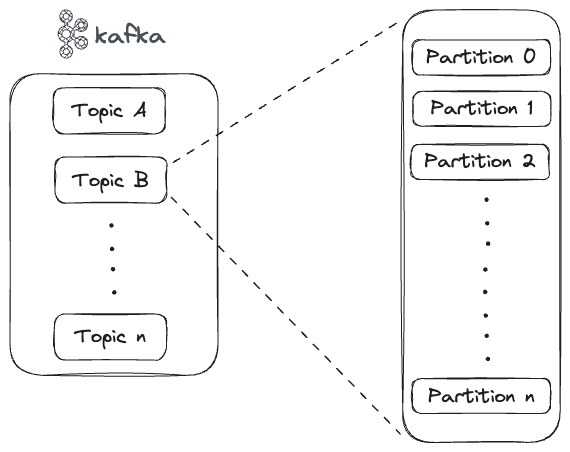
A topic which is actually only a logical grouping consists of partitions and each of these partitions can live on a separate broker in the cluster. So storing, writing and processing of messages can be split among the brokers in the cluster as shown below.
Here there are 3 topics, A, B and C each having 2 partitions.
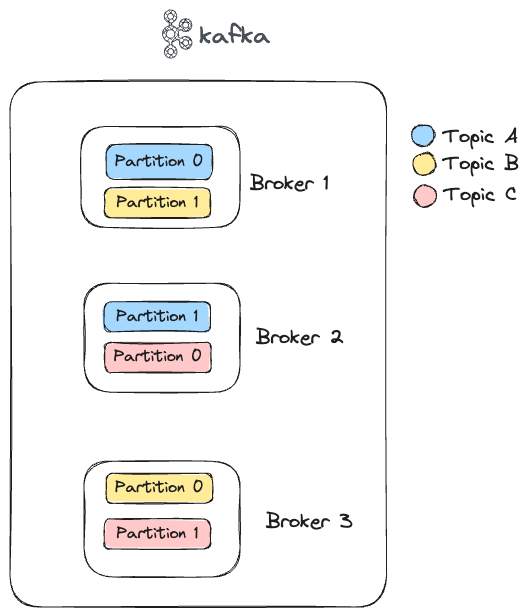
Each partition has a configurable number of replicas (typically 3) for fault tolerance. So the distribution can change as follows.
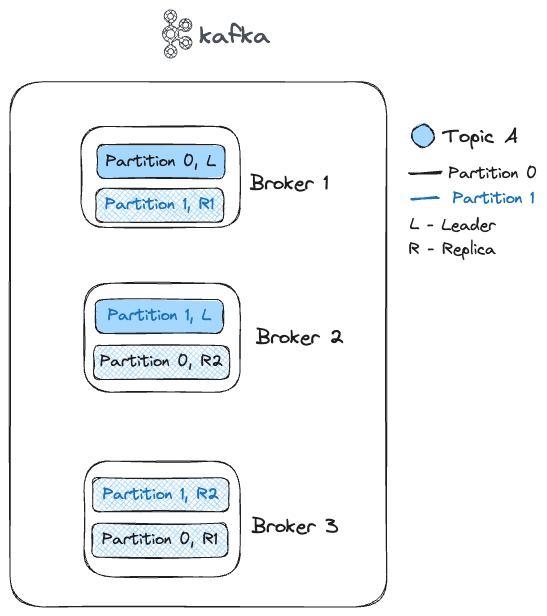
Here, I’ve taken the case for topic A and its two partitions 0 and 1 which are replicated across 3 brokers. Similarly, for topics B and C it can have their own replicas as well across the 3 brokers. One of them will be the leader(L) and the rest are the followers(R1, R2).
Producers write events to the leader partition, similarly, consumers usually consume from the leader except for some special cases(KIP-392).
As a rule of thumb, it is recommended for each broker to have up to 4,000 partitions and for each cluster to have up to 200,000 partitions [Source].
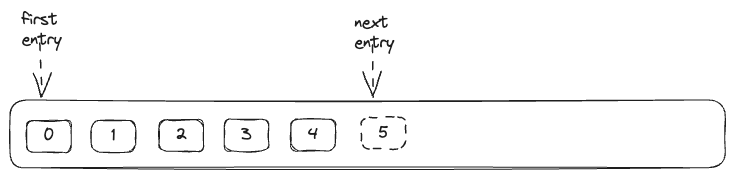
A partition consists of offsets, the first entry is written to offset 0 then 1, 2 and it continues. All written events in a partition are immutable and ordered though we can set a retention period for events written (default: 7 days).
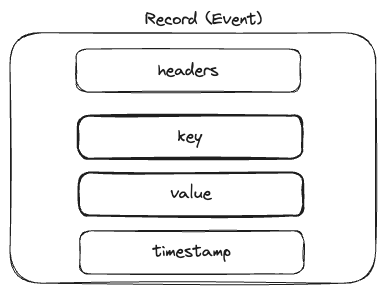
A record or an event consists of
Headers - these are optional metadata
Key - if given, ensures all events with the same key end up in the same partition
Value - relevant event data
Timestamp - creation or ingestion time
Producers and Consumers use different strategies to push and consume events from the partition.
Let’s take a look at some of the producer partitioning strategies.
Round Robin: If the message has no key it follows this, but this does not provide any ordering guarantee as the messages can be pushed to any partition.
For eg: Consider a scenario where messages from different producers are being sent on the same topic simultaneously. Due to the round-robin nature of partitioning, these messages may not be stored in the order they were produced, which can lead to variations in the message sequence when consumed.
Default strategy with key: It chooses the partition through a hash function,
hash(key) % no_of_partitions. This guarantees order since a message with the same key lands in the same partition.By carefully choosing message keys, we can ensure related data lands in the same partition, preserving order and simplifying processing.
A custom partition strategy can also be defined.
Consumers subscribe to topics and pull messages based on the offset. It can start reading from the beginning of a partition or from a custom offset. Once read successfully the consumer commits the offset to the cluster (this is stored in an internal topic __consumer_offsets) indicating that the event has been read.
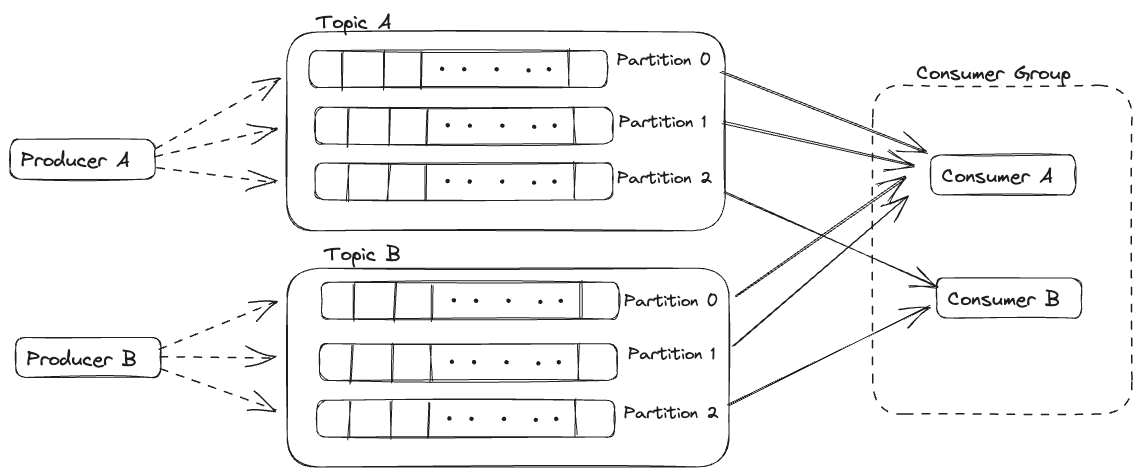
We can associate a Group ID with every consumer. All consumers with the same Group ID belong to a Consumer Group. As shown in the diagram above we have 2 consumers A and B which belongs to a Consumer Group.
For Topic A and B, Out of 3 of its partitions,
2 -> assigned to consumer A.
1 -> assigned to consumer B.
This can be the other way around as well i.e. 2 assigned to B and 1 to A.
If there was a consumer C, the assignment would have been like,
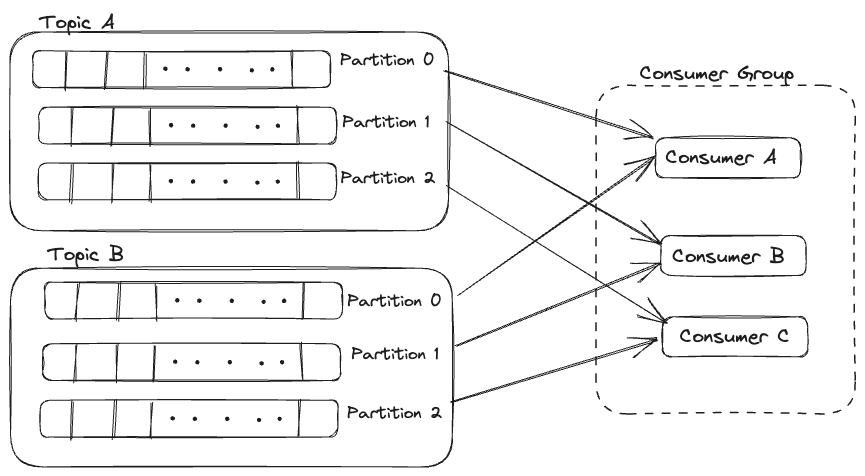
Out of 3 of its partitions,
1 -> assigned to consumer A.
1 -> assigned to consumer B.
1 -> assigned to consumer C.
Let’s add one more, consumer D
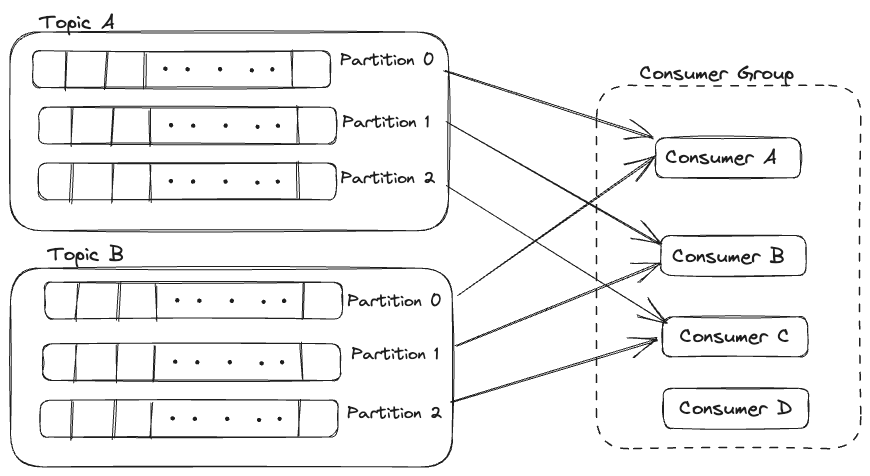
Here consumer D is idle since there are no more partitions available to be assigned to it.
Let’s take a look at some of the consumer partition assignment strategies.
Round Robin: All partitions of the subscription, regardless of topic, will be spread evenly across the available consumers.
Sticky Partition: A variant of round-robin but it makes the best effort at sticking to the previous assignment during a rebalance (Rebalance is the process in the which assignment of partition changes if a consumer joins or leaves the group or if the number of partitions in a topic changes).
Range assignment strategy: This goes through each topic in the subscription and assigns each of the partitions to a consumer, starting at the first consumer. This is useful when joining events from more than one topic the events need to be read by the same consumer.
Another concept to discuss is, Topic Compaction (Log Compaction) which ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition.
As you can see below after compaction only the latest values for each key are retained after compaction. If the use case is such that, previous messages are not needed and the state can be restored from the latest values of the keys log compaction can be enabled and this saves us a lot of storage as well.
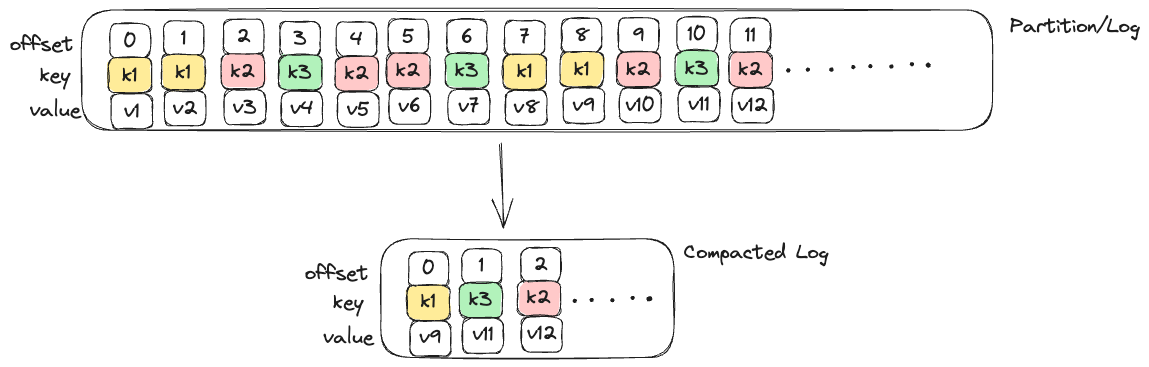
Compaction gives a more granular retention mechanism so that we are guaranteed to retain at least the last update for each primary key.
Finally, there are certain patterns and various use cases related to event processing/streaming in general. So Kafka has built a whole ecosystem around this which includes.
Kafka Connect
Kafka Streams
ksqlDB
Schema Registry (Kafka does not include a schema registry, but there are third-party implementations available).
We will discuss more on this in further blogs.
This blog was originally published on https://blog.joobisb.com/apache-kafka-a-primer